
Overview
Inside Saudi’s Tech Transformation
Get exclusive weekly insights into how the Kingdom is powering Vision 2030.
TL;DR
- Florence-2’s three-layer architecture (DaViT encoder, multimodal decoder, dynamic output heads) offers unmatched versatility and consistency across detection, segmentation, and captioning tasks.
- Zero-shot segmentation in Florence-2 allows detection and segmentation of new classes without any retraining or additional labels.
- LangSAM provides natural-language prompting for free-form segmentation, producing precise polygon masks without drawing boxes.
- A structured four-step pipeline (Ingest → Segment → Understand → Act) simplifies integration of Florence-2 and LangSAM into business workflows, making deployment repeatable and reliable.
Picture this: you upload a raw product photo to your CMS and, within a single API call, the system returns a transparent PNG mask, a JSON payload of product attributes, and a 140-character SEO blurb – ready to publish.
No bounding-box labels, no multi-model pipeline, and no frantic Slack pings to the ML team.
That “one-and-done” workflow is now possible thanks to Florence-2, Microsoft’s multimodal vision-language foundation model. It listens to plain-English prompts, sees pixels with precision, and speaks fluent JSON, HTML, and marketing copy.
But what if you need to segment an object using a natural-language description—no class labels necessary? That’s where LangSAM comes in. By accepting free-form text prompts, LangSAM lets you say things like “segment the button at the bottom right corner,” producing accurate masks without ever drawing a box.
In this read, we explore Florence-2’s architecture, its exceptional zero-shot segmentation capabilities, and a clear integration blueprint. We’ll also show how LangSAM complements Florence-2 when you need truly natural-language prompting.
Why Florence‑2 Changes the Game?
The traditional computer-vision pipeline often spirals into complexity and fails in the same frustrating way.
It requires extensive manual annotation, multiple models for detection, segmentation, and captioning, plus significant integration efforts.
Florence‑2 streamlines this tedious workflow into a single, elegant, prompt-driven solution. With just one prompt, Florence-2 simultaneously segments objects, extracts meaningful attributes, and generates descriptive text.
In just one API call, you receive multiple deliverables without additional training or model orchestration.
→ Unified task handling
Output = florence2.process( image = product_photo, prompt = ”Segment product, extract attributes, generate SEO description”, tasks=[“<SEGMENTATION>”, “<ATTRIBUTE_EXTRACTION>”,”<CAPTIONING>”] |
Zero-Shot Magic in Action
Florence-2 shines when you need to segment predefined classes instantly—no extra training required. You simply pass a class label at inference time, and Florence-2 returns precise masks and bounding boxes.
For instance, when your UX/UI design team introduces a new UI component like a “floating action button,” Florence‑2 instantly recognizes and segments it, drastically reducing manual verification.
response = florence 2.predict ( task = ‘<OPEN_VOCABULARY_DETECTION>’, inputs = ‘floating action button’ ) |
Because Florence-2 was pretrained on 126 million images and 5.4 billion annotations (FLD-5B), it can generalize to any class label you supply—cars, logos, animals, you name it. This zero-shot capability drastically cuts down on labeling cycles and model retraining.
Despite its power, Florence-2 does not support free-form, natural-language prompts for arbitrary descriptions. It only accepts class names or previously defined labels, and uses region-based inputs (clicks or boxes) for segmentation tasks.
What LangSAM Offers?
Almost all segmentation tools, even those that are built on SAM-2, require you to draw bounding boxes, draw masks, or click on regions to tell the model what to segment. This approach still forces you to predefine regions of interest with your mouse, which can be tedious and slow when you need to extract many different objects or iterate quickly on new visual concepts.
LangSAM transforms that workflow by introducing natural-language prompting for segmentation. Instead of drawing or clicking, you simply describe what you want in plain English. For example, you can ask LangSAM to “segment the button located at the bottom right corner,” and it will carve out an accurate polygon mask—no bounding boxes or manual scribbles required.
from langsam import LangSAM sam = LangSAM(model_type=”sam2-hiera-large”) masks, boxes, phrases, logits = sam.predict( image_path, text_prompt=”segment the button located at the bottom right corner”, box_threshold=0.24, text_threshold=0.24 ) |
Behind the scenes, LangSAM leverages SAM-2 (Segment Anything Model) for pixel-level precision and augments it with a GroundingDINO–based language head to map text prompts to visual regions. This combination means:
- Free-Form Text Prompts: Describe any object, no matter how novel or unusual, using conversational language.
- High-Precision Masks: SAM-2’s mask generation ensures that even intricate shapes (like textured logos or small UI elements) are segmented accurately.
- Rapid Iteration: Instead of redrawing masks, you can refine the prompt (“segment the red button next to the search bar”) to get exactly the region you need in seconds.
Because LangSAM understands language directly, it’s ideal for good ux design and marketing workflows where stakeholders think in descriptive terms (“the promotional banner with the neon call-to-action”). It greatly reduces the friction of creating segmentation masks for new or evolving UI components, product placements, or any scenario where manual annotation would be a time sink.
The 3-Layer Architecture Explained
1. Image Encoder (DaViT)
Florence‑2’s Dynamic Vision Transformer breaks images into meaningful patches and employs windowed self-attention, efficiently processing high-resolution images. It outputs rich, multi-scale feature maps critical for detailed segmentation tasks.
2. Multimodal Transformer Decoder
This central transformer layer fuses image tokens with your language-based prompts. It determines precisely what to segment, caption, or extract, and can deliver outputs ranging from structured JSON metadata to detailed HTML/CSS snippets.
3. Dynamic Output Heads
Finally, specialized output heads convert transformer outputs into actionable formats, including masks, metadata, and ready-to-deploy content, ensuring seamless integration with downstream business tools.
Technical Edge
Component | Specification | Benefit |
DaViT Encoder | Processes 1024×1024 images in 48ms (A100 GPU) | High-resolution, real-time segmentation |
Multimodal Decoder | Generates text, bounding boxes, and masks from natural language prompts | Single-model versatility |
Zero-Shot Mastery | 72.3 mAP on COCO detection without fine-tuning | Immediate deployment without extra labeling |
Implementation Blueprint
Deploying Florence-2 and LangSAM into your workflow involves four straightforward steps designed to simplify integration and maximize business impact. The overall pipeline remains the same, with Florence-2 handling class-based segmentation and LangSAM stepping in whenever you need free-form, text-prompted masks. Consider the following streamlined 4-step process:
➤ First, Ingest images from your sources—product photos, UI designs, or medical imagery—and resize them to a standardized resolution optimized for processing speed, such as 1024px.
➤ Second, Segment the images by using Florence-2’s open-vocabulary detection. Unlike traditional segmentation, no predefined categories are needed. Prompt the model with plain language to detect the elements critical to your business.
➤ Third, Understand each detected segment in greater depth by automatically generating context-aware descriptions or extracting detailed attributes using Florence‑2’s multimodal decoder.
➤ Finally, Act by exporting these structured insights directly into your business systems, such as CMS platforms, medical databases, or application development workflows, minimizing manual data handling.
This structured approach significantly improves efficiency, automating content management and providing detailed, actionable insights.
Step | Description | Example Action |
1. | Ingest: Input visual data from CMS or app screenshots. | Website screenshots from CMS |
2. | Segment: Perform open-vocabulary detection on visuals. | Identify promotional banners |
3. | Understand: Generate multimodal captions or attributes. | Detailed captioning of segmented banner |
4. | Act: Output structured JSON to CMS or analytics tools. | Automated website content updates |
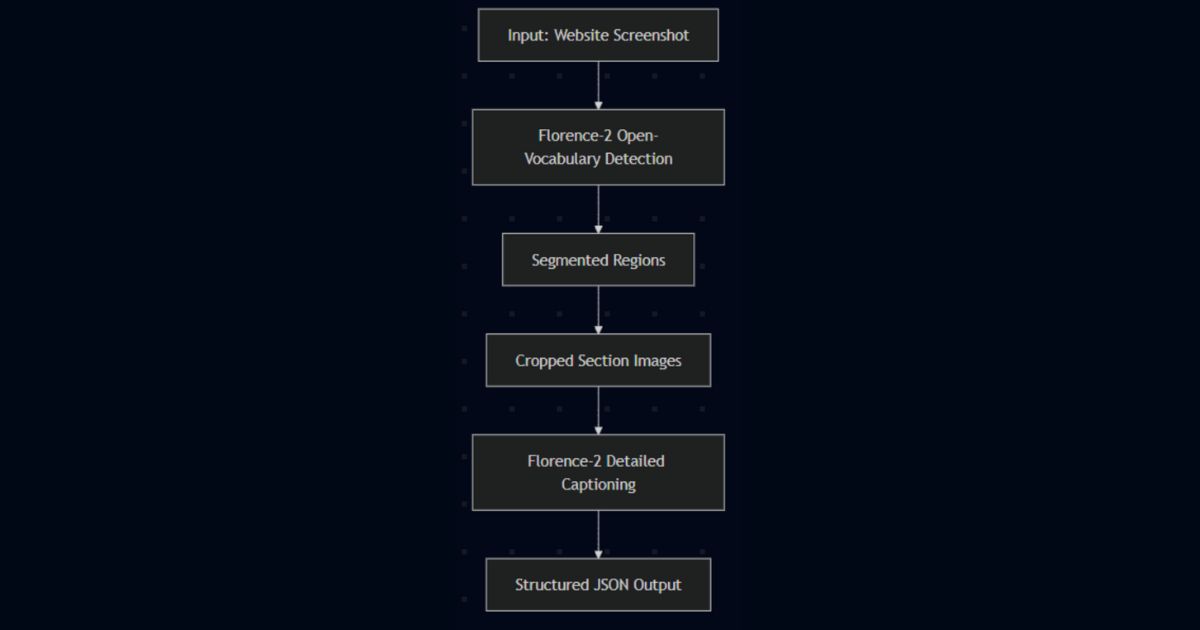
Pipeline Workflow
Where It’s Already Making an Impact?
AI Image segmentation has proven its value across various industries through multiple real-world applications. By streamlining complex visual workflows, it empowers teams to save time, reduce errors, and unleash creative possibilities that were previously out of reach.
Let’s explore some impactful use cases demonstrating how Florence-2’s capabilities translate into valuable results and where LangSAM can step in when natural-language segmentation is required.
1. E-Commerce Listing Automation
Retailers have long faced operational bottlenecks when it comes to manually tagging, categorizing, and describing product images. These tasks slow down product launches and introduce a high risk of inconsistencies.
Florence‑2 automates the entire process by segmenting product images, accurately extracting attributes like color and material, and producing SEO-friendly descriptions in one smooth pass. This not only accelerates catalog updates but also dramatically cuts down on labeling errors.
Here’s a quick example of how Florence‑2’s automated segmentation can transform your product-photo pipeline:
output = florence 2.process ( Image = product_photo, Prompt = “Segment product, extract attributes, generate SEO description”, Tasks = [“<SEGMENTATION>”, “<ATTRIBUTE_EXTRACTION>”, “<CAPTIONING>”] ) |
Outputs: Product mask (PNG) Attributes: {“color”: “rose gold”, “material”: “ceramic”} Description: “Luxury rose gold ceramic mug with ergonomic handle…” |
2. UI-to-Code Conversion
The process of transforming design mockups into functional front-end code is typically lengthy and error-prone. Florence‑2 significantly reduces this burden by interpreting UI screenshots and converting them into structured HTML/CSS code.
This process preserves pixel-perfect accuracy and slashes manual coding hours. Whether you’re dealing with a straightforward login screen or a complex dashboard layout, Florence‑2 makes it easier to maintain consistency between design vision and final implementation.
Here’s a quick example of how it accelerates software development by directly converting UI mockups into structured HTML/CSS code.
florence 2.process ( image = wireframe, prompt = “Convert to HTML/CSS with element mapping”, Tasks = “<STRUCTURED_OUTPUT>” ) |
Results:
<div class = “button” style = “top: 120px; left:30px; background: #4285F4”> <!– Detected as ‘Login Button’ → </div> |
3. Marketing & Website Optimization
Digital marketers often struggle with personalizing large volumes of promotional banners or web pages under tight deadlines.
Florence‑2 addresses these challenges by segmenting and classifying banner elements, then automatically generating A/B test variants for different layouts and messaging.
This approach reduces campaign launch times, improves targeting precision, and has been shown to boost click-through rates. Marketers can now deploy, test, and iterate creative concepts at a fraction of the usual cost and time.
4. Healthcare & Precision Analytics
When it comes to medical imaging, accuracy can directly influence patient outcomes. Florence‑2 excels at precise segmentation, identifying complex shapes and boundaries in MRI or CT scans with sub-millimeter accuracy.
This speeds up diagnostics by automating procedures such as tumor boundary marking and reduces workloads. By leveraging AI in healthcare, we are able to make faster treatment decisions, improve patient care, and ultimately save lives.
Summing Up
Florence-2’s impact on AI image segmentation and beyond is hard to overstate. By uniting tasks like captioning, detection, and segmentation under one system, Florence-2 achieves performance benchmarks that outpace specialized models.
Whenever you need flexible, free-form text prompts-like “segment the green button on the top right”-LangSAM delivers pixel-perfect masks from simple English descriptions. Together, Florence-2 and LangSAM cover both class-based and natural-language workflows, ensuring your team never hits a segmentation bottleneck.
The result? Faster innovation cycles, more intelligent automation, and a competitive edge in any field that relies on understanding images.
As AI vision technology surges ahead with models like Florence-2 and LangSAM, businesses need a trusted partner to navigate this complexity. Veroke provides AI solutions that help organizations integrate intelligent vision systems seamlessly.
Our team combines technical expertise with business acumen to support your AI adoption journey from strategy through implementation. With Veroke by your side, you can confidently harness AI to transform processes and drive innovation with a strategic approach to intelligent vision.
FAQs
1.What is Florence-2 used for?
Florence-2 is a vision-language foundation model that performs tasks like image segmentation, detection, captioning, attribute extraction, UI-to-code conversion, and structured JSON output in a single workflow.
2.What is zero-shot segmentation?
Zero-shot segmentation allows Florence-2 to identify and segment objects it was never trained on by simply providing a class label at inference time – no retraining required.
3.How is LangSAM different from Florence-2?
Florence-2 requires class labels (e.g., “coffee mug”), while LangSAM accepts natural language prompts (e.g., “segment the brown cup on the left”). LangSAM is better when you need fully natural segmentation without annotations.
4.Does LangSAM require bounding boxes?
No. Unlike other SAM-based segmentation tools, LangSAM lets you segment objects using plain English descriptions – no boxes, clicks, or scribbles needed.
5.Can these models work together?
Yes! Florence-2 handles fast class-based tasks, while LangSAM helps with natural-language precision segmentation. Together, they cover both structured and unstructured segmentation workflows.
Want to know more about our service.
Inside Saudi’s Tech Transformation
Get exclusive weekly insights into how the Kingdom is powering Vision 2030.
Transform your Ideas into a Digital Reality
Get scalable, customized solutions for your business.



